如何快速上岸數據科學家
作者:許晴程
數據科學家從 2014 年被哈佛商業評稱為最性感的職業後, 越來越多的年輕同學們投入這個行業。 作為在北美擔任數據科學家生涯規劃的導師,並且自己有多年大廠數據科學家的經驗。 我有三點建議給沒經驗且想要從事數據科學朋友們。
- 了解行業數據科學家所需要的能力。目前業界的數據科學家所需要的硬核能力(不包括軟實力),基本上是由以下四個維度所組成:
一 軟體工程能力
二 統計數學能力
三 AI 算法能力。
四 Domain knowledge
撇開 Domain knowledge 不說,現在很多公司的數據科學家做的事情並非同學們所想的,每天都在做很酷的算法。 甚麼 ChatGPT, Bert… 因為一個 Project 最多就需要幾個算法,加上現在的算法庫已經做到 developer 只需要幾行代碼,就可以完成很複雜的算法。所以只做算法的數據科學家注定發展的路比較受限。
相反地一個產品要真的上線,需要數據遷移,數據清洗,結果呈現,等等複雜的軟體工程。所以我看到一般公司裡, Title 是掛數據科學家的同學, 實際上所做的是卻是整理數據的工作。 這很正常。 所以同學們在找工作之前就必須要有一個觀念,不是每個數據科學家都能夠從事 algorithm 的工作, 就只有少數的幸運兒(通常是名校的強者) 才有辦法做到。
2. 要知道自己的能力在哪裡。 在我接觸的同學當中。一般對於自己的能力都沒辦法正確的評估。通常很兩極化。 要不是覺得自己能力很強,就是覺得自己什麼都比不上人。 這兩種看法都太過極端。 每一個人都必須要很客觀地評價自己的能力,要衡量自己在哪一個維度具有比較高的水平。譬如有些同學算法很強,所以在申請工作的時候就應僅量找算法工程師,即便如此,就像我前面所說的其他的維度也必須要有均衡的發展。因為現在 AI 變得非常熱門,以前名校 PhD 畢業能夠直接進入名企的時代已經過去了。每一個人都必須通過不同的維度底下基本的能力測試。
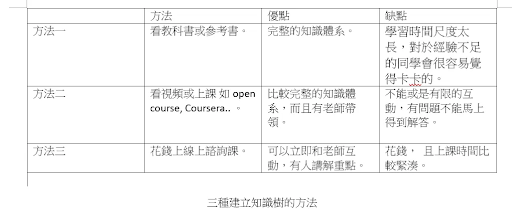
第三點必須徹底地將自己的知識點建立好。 就像是種一顆知識樹, 常常灌溉它。 這樣的好處是有累積性 。 累積性是很重要的, 在短時間內看不出它的效果, 長時間就可以看到它的好處。關於知識樹建立的方式我提供三個方法:
第一個方法,找一本書開始學習。這樣的好處是能夠地毯式的學習,但是壞處是時間尺度太慢,而且常常陷入一個自我否定的恐慌中,因為很多知識點在書中沒有辦法被很清楚的提練出來。除非你自己已經是有經驗的學習者。 這類的學習適合專門的技術, 像是特別要學習"搜索引擎" 或是 "transformer”… 等等。一般來說 能夠看書學習的同學 對於數據科學的基本功大多已經有一定的基礎了。
第二種方法是看網路上的課程: 現在網路上有很多 Open Course 可以讓同學們自己去學習。它的好處是可以用自己的速度隨時去學習。 不用感到時間的壓力。缺點是這樣的課程缺乏互動,有問題的時候沒有人可以解答或者就必須要找有經驗的朋友詢問。
第三種方法是花錢去上課 。 我比較建議給剛開始入門的小白同學。這樣的方式對於一個剛入門的同學來說是比較容易上手的。而且在課堂上也有更多的機會與老師們能夠互動。雖然這樣的方式需要花一點錢。但是對於剛入門不知道重點在哪的同學來說,這是一個最好的方法。
----
作者許晴程為 81年畢業校友,台大物理系,台大物理學研究所碩士,德國 Ludwig-Maximilians-Universität München 博士。
原文刊載於 https://medium.com/@sunny.reis/如何快速上岸數據科學家-2eec8266c023
.jpeg)


